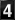 accesses since March 19, 1999
accesses since March 19, 1999  copyright notice
accesses since March 19, 1999
copyright notice
accesses since March 19, 1999 Hal Berghel, University of Arkansas
By the mid-1990's, the World Wide Web (or, simply, the Web) became the most active part of the Internet. According to the NSFNET Backbone statistics, the Web moved into first place both in terms of the percentage of total packets moved (21%) and percentage of total bytes moved (26%) along the NSF backbone in the first few months of 1995. This placed the Web well ahead of the traditional Internet activity leaders, ftp (14%/21%) and telnet (7.5%/2.5%), as the most popular Internet service.
Figure 1 plots the recent evolution of the Web, Gopher and FTP as a percentage of overall network packet transmission and volume of information along the NSFNET backbone. This is the most recent data available since the NSFNET has subsequently changed to a distributed network architecture involving multiple Network Access Points (NAPs).
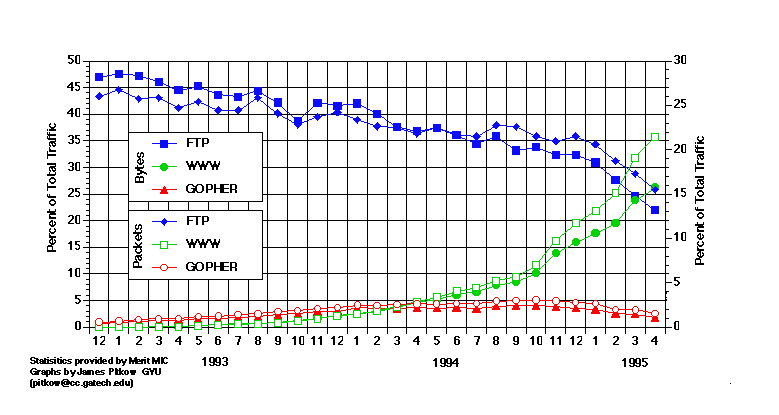 Figure 1.Comparison of three popular Internet protocols by volume
of information and number of packets transmitted along the NSFNET backbone.
Comparison based on percentage of total. (Adapted from Pitkow: GVU NSFNET
Backbone Statistics, 1995)
Figure 1.Comparison of three popular Internet protocols by volume
of information and number of packets transmitted along the NSFNET backbone.
Comparison based on percentage of total. (Adapted from Pitkow: GVU NSFNET
Backbone Statistics, 1995)
The rapid escalation of Web use seems to be a result of at least three characteristics:
The Web is an application of the client-server model for networked computing systems which support Internet protocols. The client, to be discussed below, handles all of the interfacing with the computing environment and temporarily stores information for presentation to the user. The networked servers are the information repositories and hosts of the software required to handle requests from the client.
The Internet, a nearly ubiquitous collection of packet-switched digital networks, supports dozens of communications and networking protocols. Table 1 lists some of these protocols. The Web uses the protocol-pair, HyperText Transfer Protocol (HTTP) and HyperText Markup Language (HTML). The former establishes the basic handshaking procedures between client and server, while the latter defines the organization and structure of Web documents. At this writing, the current HTTP version is 1.0 while adoption of version 3.2 of HTML should take place by late 1997.
PROTOCOL NAME (abbreviation/version or standard): DESCRIPTION
Basic communication (or data-delivery) protocol for packet-switched computer networks (e.g., Internet). IP packets prefix headers of at least 20 bytes, which specify source and destination IP addresses as well as format information, to the actual data. IP is a potentially lossy and verbose transmission protocol.
Protocol for ensuring reliable transmission of IP packets. TCP checks for lost or duplicate packets (alt: datagrams), requests re-transmission of packets when required, and puts the packets back in order on receipt
Protocol for implementing a simplified application of ISO Standard 8879:1986 Standard Generalized Markup Language (SGML) for the Web. HTML defines the organization and structure of Web documents. HTML uses primitive ASCII "tagging" convention to define elements and features.
Transactions protocol for client-server communication on the Web. HTTP relies on TCP/IP for transport/routing across the internet. HTTP is said to be a "generic" and "stateless" protocol, meaning, respectively, that it accommodates non-http protocols (e.g., ftp) and disconnects client-server connection immediately after each transaction (vs. ftp and telnet)
Protocol for the implementation of a global distributed database on Internet servers which, collectively, map symbolic Internet names onto specific IP addresses. The client interface to DNS is a program called a "resolver" which traverses the DNS servers until it can return the appropriate address record to the client.
Platform-independent, command-response protocol for transferring files between computers. Initial client-server connection exchanges control information. Subsequent connection exchanges data in generic form.
Interconnection protocol which establishes a remote client as a virtual extension of a server following the Network Virtual Terminal (NVT) model. Both client and server behave as if connection is local, even though connection is via the Internet.
A typical Web client-server transaction would take place in a sequence similar to the following:
This defines the general case where the client specifically requests information which must be computed from the server. In the much simpler case where the client only requests media on the server, steps (3)-(6) don't apply.
The connection which is established between client and server relies on the unique Internet Protocol (IP) numeric addressing scheme. Each node of the Internet is currently identified by a four-byte address (e.g., 128.328.18.5), defining a total address space of 256**4 = 4,294,967,300 which is rapidly becoming depleted because of the enormous popularity of the Internet and the Web. For convenience, the Internet has a Domain Name Server (DNS) system which translates URLs into unique IP addresses (see above).
The networking aspects of Internet communications will not be dealt with here except to mention that the Internet's communications metaphor is packet-switching (vs. the circuit switching metaphor of basic telephony) which is managed by the Internet's communication software suite, Transmission Control Protocol/Internet Protocol (TCP/IP). Plans are currently underway to modify this suite to accommodate higher-bandwidth networking. The new communication protocol, Internet Protocol Next Generation (IPNG) will extend the capabilities of the current Internet Protocol version 4 to include packet tunneling (where Internet paths to the destination are specified in the packets as well as the destination addresses), 128-bit IP addresses (8 8-bit segments vs. the present 4 8-bit segments), 2**32 individual multicast addresses, and support of connection-oriented, asynchronous Transfer Mode (ATM) networks. This will bring about many changes in the use of the Internet early in the next century.
While many other Internet protocols (e.g., file transfer protocol (ftp), Gopher, Network News Transfer Protocol (NNTP)) have multi-protocol capability, only the native, Web "killer" protocols, HTTP and HTML, have provided versatility and robustness sufficient to generate and retain the interest of large numbers of major media providers and software developers. As a result, in just a few years the Web has become the medium of choice for general-purpose network information exchange.
The Web was conceived by Tim Berners-Lee and his colleagues in 1989 as a shared information space which would support collaborative work. Berners-Lee defined HTTP and HTML at that time. As a proof of concept prototype, Berners-Lee developed the first Web client navigator-browser in 1990 for the NeXTStep platform. Nicola Pellow developed the first cross-platform Web browser in 1991 while Berners-Lee and Bernd Pollerman developed the first server application - a phone book database. By 1992, the interest in the Web was sufficient to produce four additional browsers - Erwise, Midas and Viola for X Windows, and Cello for Windows. The following year, Marc Andreessen of the National Center for Supercomputer Application (NCSA) wrote Mosaic for X Windows which soon became the browser standard against which all others would be compared. Andreessen went on to co-found Netscape Communications in 1994 whose current browser, Netscape Navigator, is the current de facto standard Web browser.
Despite its original design goal of supporting collaborative work, Web use has become highly variegated. The Web is now extended into an incredibly wide range of products and services offered by individuals and organizations, for commerce, education, entertainment, and even propaganda. A partial list of popular Web applications includes:
Most Web resources at this writing are still set up for non-interactive, multimedia downloads. This will change in the next decade as software developers and Web content-providers shift their attention to the interactive and participatory capabilities - of the Internet, of the Web and of their successor technologies. But for the moment, the dominant Web theme seems to remain static HTML documents, not infrequently augmented with arguably gratuitous animations and sound.
We observe that in the mid-1990's the Web environment was complemented in two important respects. First, with the development of "plug-ins" which behave in much the same way as spawnable perusers and players, but which don't require the use of the browser launchpad. Second, with the advent of executable content made possible primarily by the Java development language whose binary object modules are executable on the client directly from Java-enabled Web browsers. Not surprisingly, this latest extension which involves executing foreign programs which have been downloaded across the networks is not without security risk.
The first extensive reporting on Web use began with the first World Wide Web Survey in January, 1994 conducted by Jim Pitkow and his colleagues at the Graphics, Visualization and Usability Center at Georgia Tech. These surveys continue to this day at six-month intervals, the latest of which is the 6th survey which is summarized here.
The average age of Web users is 34.9 years, steadily increasing over the past few years from 32.7 years in the fourth survey. Approximately one-third of the users are female (31.4%), up from 5% for the first survey in 1994, and over half (56.1%) have college degrees. 52.5% of all users have either computing or educational vocations. European users tend to be slightly more male (80.2%) and most likely to be in education or computing (68%). English remains the primary language of Web users (93%).
From the client's perspective, 66% of all Web users claim a Microsoft Windows client as their primary computing platform, followed by Macintosh (26%) and Unix (3.6%). Over half have monitors (a) at or above 800x600 resolution (53.4%), and (b) 15" or larger ((53.9%). The majority of platforms (58.4%) support at least 16-bit color. In excess of 80% of the users surveyed indicated a preference for Netscape's browser, while 12.2% preferred Microsoft's Internet Explorer. Internet Explorer's 9% gain in market share from the previous survey corresponds to an equal loss in market share by Netscape during the same interval.
Direct Internet connections are still in the minority, with 71.6% of all Web users using modems with transmission speeds of 28.8Kb/sec or less.
36.1% of users have begun their Web use in the past year, down from 43.1%, 60.3% and 50.2% in the 5th, 4th, and 3rd GVU Surveys, respectively, reflecting that first-time Web utilization may have peaked. The fact that 42.4% have been using the Web for 1-3 years may signify a level of technology maturation. Most Web use now takes place in the home (63.6%), a significant increase over previous surveys. This suggests that the Web has achieved a significant level of acceptance and pervasiveness within the computer-use community.
Primary Web use includes:
Primary Web-related problems include:
It should be emphasized that the GVU user-profile surveys are non-random and self-selecting, and their results should therefore be conservatively and cautiously interpreted. Random surveys of Web use have been conducted, however, but with mixed results. The data in Table 2 corroborate the difficulty inherent in producing reliable Internet use data from such random surveys. For further insight, see Hoffman, et. al.
name(date) of survey :: estimated Internet users
Client-side software for the Web remains primarily browser-centric. Web browsers provide the stability and evolutionary momentum to continue to bring together vendors of new multimedia perusers and executable content. This trend began in 1994 with the advent of so-called "helper apps" - multimedia perusers and players which could be spawned via the Web browser's built-in program launchpad. By year's end most Web browsers included generic launchpads which spawned pre-specified multimedia players based on the filetype/file extent (.WAV designated MS Window's audio file, .QT designated Quicktime, etc.).
The generic launchpad was a significant technological advance for two reasons. First, it de-coupled the evolutionary paths, and hence the development paces, of browsers and multimedia. The first multimedia Web browsers relied entirely on internal media perusers, thereby creating a bottleneck as the pace of development of new multimedia formats exceeded that of the internal perusers. By de-coupling, both browser and multimedia developers could advance independently without fear of incompatibility.
Second, generic launchpads spawn external processes which execute independently of the Web browser and hence render the multimedia in an external window. This process-independence discourages the development of helper apps that are proprietary to a particular browser, which led to the rapid growth of freeware, shareware and commercial helper apps that are now available for popular client platforms. That the helper apps could be used in isolation of the browser became a collateral advantage for easy perusal of local multimedia files as well.
This generic, browser-independent approach toward rendering multimedia would be challenged twice in 1996, by "plug-ins" and by "executable content."
Plug-ins (or add-ons), as the name implies, are external applications which extend the browser's built-in capability for rendering multimedia files. However, unlike helper apps plug-ins render the media "inline" - that is, within the browser's window in the case of video, or with simultaneous presentation in the case of audio. In this way the functionality of the plug-in is seamlessly integrated with the operation of the browser. Plug-ins are proprietary and browser-specific because of this tight integration. Some of the more popular current plug-in technologies are Web telephony, virtual reality and 3-D players, and real-time (or, "streaming") audio and video.
Executable content continues the theme of tight integration between multimedia peruser and browser, but with a slight twist. In the case of executable content, the multimedia and the peruser are one. That is, an enabled browser will download the executable files which render the multimedia and execute them as well, all within the browser's own workspace on the client. The practical utility of having both media and player in one executable file stimulated the rapid development of this technology despite growing concerns for security.
Since, in theory at least, foreign executables may be malevolent as well as benevolent, well-behaved executable content binaries are "hobbled" to prevent malevolent programs from achieving client-side execution. However, by early 1997, security breaches of content-enabled browsers were still being routinely reported. While there are several competing paradigms for Web-oriented executable content, including JavaScript, Telescript, and ActiveX, the cross-platform language, Java, was the clear environment of choice in early 1997.
By the mid-1990's, the an ever-increasing array of available Web resources began to work against efficient access in a significant way. By mid-decade, the number of Web sites indexed by the popular search engines approached 100 million, thereby flooding the Web with a veritable tidal wave of information. Information overload - having to deal with more information than one could comfortably process - became a Web reality.
At this writing, there are more than 125 search engines (see Figure 2) available to Web users, each with its own search characteristics. A recent addition to the Web has been the "meta-level" search engine which utilize several other search engines to locate the information. There are also special-purpose indexing tools which categorize Web resources (as a home page, by document type, etc.)
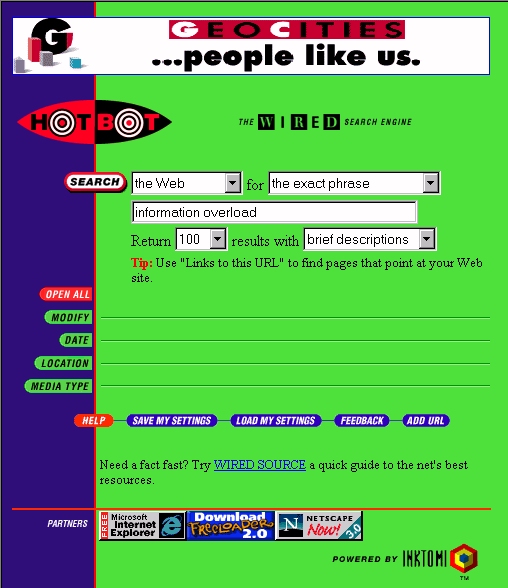 Figure 2.The interface of one of the more advanced, current search
engines, HotBot. This search produced 54,466 matches.
Figure 2.The interface of one of the more advanced, current search
engines, HotBot. This search produced 54,466 matches.
In operation, search engines behave like the search utility in a typical desktop productivity tool. Most search engines support Boolean queries through an interface that is built around a CGI (Common Gateway Interface) form. Typically, this involves passing the query parameters from the form to the server as a CGI query_string variable. The server then searches the index database and reports matches to the user in the form of a dynamically-created HTML document. This index is produced by the server's network indexer, which utilize a variety of utilities for traversing the Web in search of indexable (if not always useful) information (e.g., spiders, wanderers, crawlers, ants, robots, etc.)
The strength of today's powerful search engines actually works against their successful deployment. The exponential growth of the Web (in terms of clients connected, number of sites, and number of files) has produced a great deal of information that is that is of little utility or long term benefit to the overwhelming majority of Web information consumers. The Web now consists of an enormous number of vanity homepages, narrow-interest documents, and insubstantial and inaccurate information resources which inhibit productive searching. The most efficient searching would result if the Web's resources were indexed, graded and carefully categorized as they were being posted. But such prescriptivism runs counter to the Web philosophy of fostering an open, uninhibited, free exchange of information, it is unlikely to ever take hold.
Thus, while search engines may achieve some additional effectiveness by refining their indexing behavior through careful document parsing integrated with full use of the HTML <META> and <TITLE> tags, the free-wheeling spirit behind Web resource development will likely prevent search engines, as they are now designed, from ever becoming reliable, stand-alone Web information retrieval tools.
Information retrieval tools which can mitigate against the problem of information overload may be categorized broadly by the nature of their computing host: server-side or client-side. We illustrate these categories of tools with an example of each.
One server-side approach which holds great promise is information agency. "Agents" (aka software robots, softbots, bots) are computer programs which roam the Internet on behalf of an owner, ferreting information and taking actions as situations warrant. If such agents are competent and trustworthy, they may free the owner from much of the actual navigation and searching involved in locating Web resources.
Information agents of many types are currently being deployed for the location, manipulation, monitoring and transmission of a variety of Web and Internet resources. They operate within several Internet protocols). If current research is successful, it is entirely possible that information agency will be one of the major growth industries in network computing by the turn of the century.
While there is nothing to prevent agents from being deployed on the client, there seems to be a general feeling that it is wise to do as much screening as possible on the servers in order to diminish the volume of information reported to the user and to minimize bandwidth drain on the networks. As a result, server-side agency is predominant at the moment.
One proposed enhancement for the client-side is information customization. As we use the term, information customization has five basic characteristics: (1) it is always performed on the client side, (2) it is specifically designed to maximize information uptake, rather than filter or retrieve, (3) it "personalizes" documents by such techniques as extraction, (4) it is never done autonomously, and (5) the capability of non-prescriptive, non-linear document traversal is always added by the software - that is, for that specific user. Condition (2) sets information customization apart from traditional information filtering and retrieval, while (4) would set it apart from client-side agency, and (5) would distinguish it from traditional non-linear document traversal systems (e.g., hypertext).
Information customization software as envisioned here would make it possible for users to "speed read" documents through non-linear traversal, in much the same way as with hypertext. But with information customization, the non-linearity would be non-prescriptive - that is, added for the user by the client software rather than by the information provider at the time that the document is created. Prototypes of information customization clients integrate with Web browsers as well as other desktop applications and are document-format independent.
Typically, Web information access is "pull-phase", meaning that the information is sought after by the user. The navigation through cyberspace by URL is a paradigm case of pull-phase access. During 1996 several experiments in "push-phase" access were undertaken.
Push-phase or, more properly, "solicited" push-phase access, involves the connection of clients to netcasting network information providers. As one example, Pointcast (www.pointcast.com) users connect to a central digital "transmitter" that connects the end user to a variety of different information feeds (Reuters, Business Wire, People Magazine, etc.) integrated on Pointcast's server. On the client side, the Pointcast peruser operates as an autonomous window providing downloaded information from selected feeds. Pointcast follows in the tradition of the cable television industry by consolidating and distributing information (including advertising) from one distribution source to many subscribers.
Marimba Corporation's (www.marimba.com) approach to solicited push, however, is quite different. Here an analogy with direct broadcast television satellite systems is closer. Marimba's proprietary client-server software, Castanet, allows the end-user to connect to an arbitrary number of third-party server "transmitters" from the client side. The connection between a Castanet client "tuner" and each of the Castanet server "transmitters" is called a "channel". In basic terms the channel amounts to network access to some server's file structure. Where Pointcast may be thought of as a 1:many network transmitter, Castanet would be many:many. An illustration of Castanet appears in Figure 3.
 Figure 3.Marimba's Castanet Client. Note three channels are established,
the first and third of which are active in separate windows. Interactivity
between client and server is automatic and autonomous for each channel.
Figure 3.Marimba's Castanet Client. Note three channels are established,
the first and third of which are active in separate windows. Interactivity
between client and server is automatic and autonomous for each channel.
Push-phase information access is an interesting extension of the Web because it is the first Web application which departs from the browser-centric model, where the Web browser either spawns other applications or runs the application as an extension of itself. Both Pointcast and Castanet are browser independent. Castanet is the most supervenient with respect to the browser in that each channel-application (a) performs autonomous local processing, (b) enjoys persistent, client-resident storage, and (c) updates both data and program upgrades differentially, by sending only those file which are new or have been changed.
Castanet differential updating is client-initiated (vs. Pointcast), which facilitates authorized transmission through server firewalls. Castanet is both a significant and robust departure from the browser-centric approach to client-connectivity. Exactly the opposite was true of the short-lived, Java-enhanced browser, Hot Java).
At this writing, Netscape, Marimba and Pointcast have announced plans to collaborate on meta-push technology which will integrate all three technologies and services in a common intranet client, Constellation. If successful, this technology should be well-entrenched by the end of this century.
The overwhelming popularity of the Web produced development of client-side Web products at a breathless pace in the 1990s. This caused a race-for-features competition between browser developers that became known as the "browser war." It is interesting to note that the early, pioneering Web browsers, Erwise, Midas, Viola, and Cello were early casualties of the war. Even Mosaic, the Web browser which made the Web viable, lost its leadership role by 1994 when rival Netscape offered a succession of more feature-rich, freeware alternatives. According to the GVU Web Surveys, Mosaic went from a 97% market share in January, 1994 to less than 3% two years later. This illustrates just how unforgiving the Web audience is regarding perceived technology deficiencies in their Web browsers. It also illustrates that product life cycles can be very short in cyberspace. At this writing, the Web browser market is dominated by Netscape, with a secondary presence held by Microsoft's Internet Explorer.
Although Web browser technology is mature, it remains in a state of flux as new Internet and Web technologies (e.g., plug-ins, push-phase access tools, integrated email) are put forth. This will continue for the foreseeable future as additional media formats and applications are seen as useful complements to the Web experience. In the main, Web browsers have converged on HTML 3.2 and HTTP 1.0 compliance, differing primarily in terms of the nature of the extensions beyond these standards which they seek to implement. Even desktop "office suites" (e.g., Microsoft Office, Lotus SmartSuite, Corel Office Professional) are now HTML- and executable content-enabled.
Although not covered here because of the browser-centricity of client-side Web software, it should be mentioned that scores of other Web utilities exist for the client side. These include, but are not limited to, browser enhancers and accelerators which employ "look-ahead" download strategies, Internet fax utilities, off-line browsers and automated downloaders, client-side search utilities (vs. server-side search utilities covered above) and Web site backup tools.
There is no question that the enormous popularity of the Web will continue in the near term. The commercial potential of the Web will also continue, encouraging even more innovation. Much of that innovation will take place on the client side as developers seek to market these tools to the burgeoning numbers of computer users.