 accesses since January 22, 2002
accesses since January 22, 2002 copyright notice
copyright notice
 link to published version in the Communications of the ACM, April, 2002
accesses since January 22, 2002
link to published version in the Communications of the ACM, April, 2002
accesses since January 22, 2002
Based on the positive feedback I received regarding my column on "Caustic Cookies" (CACM, April, 2001), I conclude that there is a genuine interest in the technical aspects underlying privacy and security issues relating to Internet use. Since Caustic Cookies seems to have been a hit, I'll continue this discussion where I left off.
As I was saying last April, the Web is all about a pair of killer Internet protocols - HTML and HTTP - that define, enable and constrain Web applications. HTTP is the application layer protocol that sits on top of the Transmission Control Protocol (TCP) which, in turn, sits atop the Internet Protocol (IP). The collection of utilities relating to these protocols that reside between the physical communications layer of the Internet, and the productivity tools that we use to get work done (e.g., Web browsers and email clients) is called the TCI/IP protocol suite (aka protocol stack).
You may recall that last April we began with the observation that the HTTP part of this protocol suite is "stateless." Under the typical scenario, this means that once an initial communication exchange between a client and a server is completed, the connection between them is dropped. This communication exchange is all built around what is commonly called the "TCP 3-way handshake," the motivation for which results from the fact that IP is "lossy" - i.e., if a packet gets lost in an IP transmission, it's gone forever. TCP overcomes this deficiency by keeping track of each leg of the communication exchange. At its most simple level, the 3 way handshake works something like this.
Stage 1 - the SYN phase
A client sends an initial synchronizing (SYN) "packet" to some server with an initial sequence number (ISN) = x
Stage 2 - the SYN + ACK phase
The server accepts the SYN packet from the client, and sends an acknowledgement back with an ISN =y and alerts the client that it awaits another packet from the client with an ISN of x+1
Stage 3 - the ACK phase
The client accepts the SYN+ACK packet and sends an ACK packet back to the server with an ISN of x+1
Now both client and server are connected and can begin tri-phase dialogs.
Note that in this exchange data persistence ends at Stage 3, so if we're to build upon previous dialogs, we'll have to do it by echoing the contents of previous communications. That's why the Web community began thinking about State Management Mechanism's in the mid-1990's. The primary state management mechanism they came up with was the "cookie" (see sidebar).
The Causticity of Cookies
Cookies are used by Web applications as a surrogate for the current state of communication. They have the following properties:
(1) They are binary data stored on the user's computer hard drive(s).
(2) The data will likely be either encoded or encrypted (i.e., the casual observer
will not be able to understand the contents).
(3) The content of each cookie
is determined exclusively by the server.
(4) Cookies can consist of up to 20
strings of 4,096 bytes in length (at least in the original Netscape proposal
that was initially adopted by the Internet Engineering Task Force).
(5) Cookies
can and do record store "clickstream" information about the user's Web browsing
habits.
(6) Cookies can be shared by third-party Web hosts with neither the
user's knowledge or permission. (Not surprisingly, these are called "third-party"
cookies.)
(7) They may be invoked by malicious or poorly designed servers to
produce denial-of-service attacks ("cookie storms") that can disrupt applications
and normal network traffic.
(8) The user may not exercise control over the ultimate destination of cookies.
This is called "cookie leakage."
(9) There is no
control over the content of a cookie. Specifically there is no way to prevent
a cookie from containing contain sensitive, classified or otherwise secure or
private information. In fact, cookies routinely store session ids, USERids and
passwords.
(10) Web browsers may store cookies from unvisited sites without
the user's knowledge or permission.
(11) Browsers do not allow you to cancel
cookies that were accepted prior to disabling cookie acceptance in your browser.
This has to be done manually (in the parlance of netizens this is called "tossing
your cookies".
(12) Cookies are stored in a variety of places on your hard drive
- in cookie directories under user folders within "documents and settings" directories,
in bookmark folders like "Internet_www_related", etc.
(13) Netscape and Microsoft
handle cookies in different ways, so it is not possible to use a one-size-fits-all
strategy to manually manage them in both environments
This behavior causes some of us to call into question the desirability of using cookies in the first place. In my view, to borrow a phrase from Dykstra, cookie technology is a mistake carried through to perfection - not because the concept of transaction management is misguided, after all there is nothing wrong with the concept of an e-commerce shopping cart, but because this paradigm was set up with inadequate protections and safeguards for end users. It should be noted that the Clinton administration banned cookies from federal Websites in the absence of "compelling need" to the contrary in June, 2000.
So one may imagine the members of the IETF Working Group on cookies trying to balance the need for Web transaction management with the vulnerabilities associated with the cookie properties discussed above. Alternatives to cookies such as URL encoding, the use of HTML hidden fields, or storage on the server side seemed fraught with difficulties, so perhaps they chose the path of least resistance with the hope that the Web world would behave with some concern for individual privacy and security. After all, hope springs eternal, even on the Internet.
Now for the Bad News.
It's time for a reality check. First, every Web "handshake" between client and server is potentially invasive. To illustrate the point, on January 15, 2002 I connected to Amazon.com with the default settings of my Internet Explorer Browser invoked just as it came from the developer. Note that entering the URL www.amazon.com produced this "extended URL" with some additional information embedded: http://www.amazon.com/exec/obidos/subst/home/home.html/103-9484532-4674260. We haven't even shopped for anything and already some user-auditing is taking place. That apparent plaintext number appended to the extended URL is curious, isn't it? Oh, well, isn't a URL just ephemeral data in a browser window?
Here the proverbial plot thickens. Unbeknownst to us, a cornucopia of temporary Internet files were dumped on our hard drive (see Figure 1). Assuming that there's nothing insidious (like Web bugs - an unwise assumption to make, by the way) embedded in the graphics, the only real penalties are the waste of 100kb of disk space and the fact that we've permanently stored the address of the cookie administrator at Amazon.com on our hard drive. I would prefer to retain the 100kb of disk and remain anonymous to cookie administrators, but we'll write this off to experience, too.
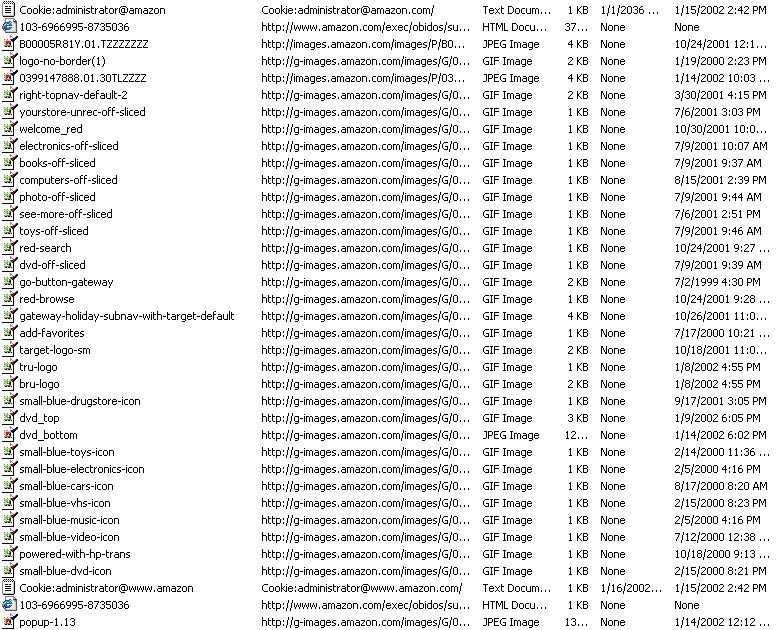
FIGURE 1: The Temporary Internet files resulting from a single access to www.amazon.com
But this is just the beginning. In addition, to the mysterious string added to the URL and the 100kb of Web guano deposited on my hard disk, two cookies were deposited on my hard drive as well (see below).
Cookie 1:
seenpop
1
www.amazon.com/
1600
1778814848
29466237
3595971744
29466136
*
Cookie 2:
session-id
103-9484532-4674260
amazon.com/
1536
3392438272
29467418
3569411744
29466136
*
session-id-time
1011686400
amazon.com/
1536
3392438272
29467418
3569571744
29466136
*
ubid-main
430-0087201-7219178
amazon.com/
1536
2916341376
31961269
3571131744
29466136
*
x-main
hQFiIxHUFj8mCscT@Yb5Z7xsVsOFQjBf
amazon.com/
1536
2916341376
31961269
3571131744
29466136
*
Let's see if we can figure out what some of this stuff means. First, we observe that both cookies are linked by some common field values. This suggests some sort of candidate key for a database. Hmmmm. I wonder if there isn't a transaction database in the background. Second, we note that there's a field identified as a session id in the second cookie. Where have we seen that before? Yep, that was the mysterious number at the end of our extended URL. This session id serves essentially the same role at the applications layer that the sequence number did within the TCP/IP protocol suite - it is part of the authentication process that the application goes through to keep track of the session activity, and link it to a user and an activity log. Now things are beginning to make sense. If we have a transaction database, and an authentication number issued to a user, we probably have identified at least part of a gateway into the database. What's more, when I view the "source" of the downloaded page from Amazon.com (Figure 2), I find that same session id number seems to be added to virtually every link on the page. Take a look at the following HTML fragment for one of the image maps.
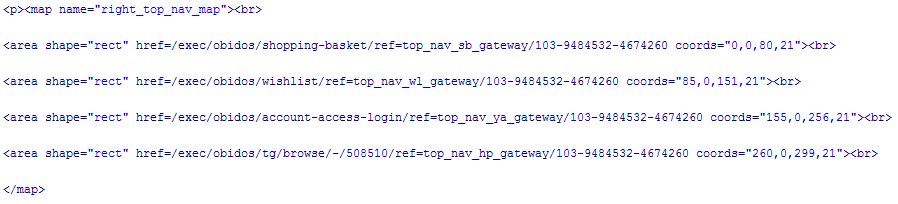
Clearly the magic number 103-9484532-4674260 is a core ingredient of the transaction information that is being used by Amazon.com about my current activities.

FIGURE 2: This downloaded page from Amazon.com betrays a bounty of hidden data when viewed as HTML source.
Hijacking the Web
We've reached the point of cascading absurdities. In my last column on cookies, we discovered that cookies are well-intentioned mistakes. Now, we find that cookies are just part of the quagmire we get into when we engage in poorly thought through TCP/IP state management. In the example in the previous section, we found that there are several pieces of information about us and our Web activities that can be pretty much spread around cyberspace.
Consider the session id. This one piece of information appears in the extended URL, two different cookies, and the actual HTML contents of the Web page delivered. What is to prevent a hacker from changing these values and spoofing some other session id? In a word, nothing. That is one of the primary ways that hackers use to hijack Web sessions. This could be done by modifying the cookie with a text editor and then re-connecting to the Website, changing the values in the extended URL, or even modifying the hard-coded information after saving the HTML page and then reloading it in the browser. A little trial and error can produce a real mess for innocent victims.
What could one achieve by doing this? For one, hijacking the session id may reveal enough of the contents of records about users and their behavior to allow a dedicated evil-doer to circumvent the application-level authentication and pretend to be someone else. A truckload of stolen plasma monitors here, a 7-digit withdrawl there - it all adds up. Your imagination can complete the story.
This is a disaster in the making, I hear you cry. Not surprisingly, I've saved the worst for last. If we weren't vulnerable enough, there is an automated environment that takes all of the busywork out of session hijacking - specialized proxy servers. Proxy servers are conduits between the client (e.g., Browser application) and the server. The proxy server maintains a complete communication stream at both ends. But because it's an intermediary between client and server, it has the capability to intercept and alter the information as it's passed back and forth within the communication stream. Such valued morsels as session ids, cookie contents, transaction information, prices, amounts, account numbers, passwords, etc. are all fair game. Any session credential exchanged in the communications that is in plaintext can be easily altered. If the meaning of the information isn't clearly identified, experimentation is called for Further, Secure Sockets Layer (SSL) and other encryption environments are of no use because the Hijacking takes place at the applications layer above SSL. Hackers have access to several different types of proxy servers that have the built-in capability of editing and transmitting session information in real time.
Actually, there's more to the story, but we'll have to deal with topics like account harvesting and database invasions in a later column.
I'll leave you with this thought: in the world of online banking and electronic commerce, the price to be paid for personal security is eternal vigilance.
I admitted my ignorance in last year's column on the origins of the term "cookie." Fortunately, David Kristol filled me in. As David reminded me that the term has had a long history in computer science, and pointed me to verion 4.2.9 (January, 2000) of Eric Raymond's online "Jargon File". Here are two entries from that source that are relevant to our discussion:
magic cookie n.
[Unix; common] 1. Something passed between routines or programs that enables the receiver to perform some operation; a capability ticket or opaque identifier. Especially used of small data objects that contain data encoded in a strange or intrinsically machine-dependent way. E.g., on non-Unix OSes with a non-byte-stream model of files, the result of ftell(3) may be a magic cookie rather than a byte offset; it can be passed to fseek(3), but not operated on in any meaningful way. The phrase `it hands you a magic cookie' means it returns a result whose contents are not defined but which can be passed back to the same or some other program later. 2. An in-band code for changing graphic rendition (e.g., inverse video or underlining) or performing other control functions (see also cookie). Some older terminals would leave a blank on the screen corresponding to mode-change magic cookies; this was also called a glitch (or occasionally a `turd'; compare mouse droppings). See also cookie.
cookie n.
A handle, transaction ID, or other token of agreement between cooperating programs. "I give him a packet, he gives me back a cookie." The claim check you get from a dry-cleaning shop is a perfect mundane example of a cookie; the only thing it's useful for is to relate a later transaction to this one (so you get the same clothes back). Compare magic cookie; see also fortune cookie. Now mainstream in the specific sense of web-browser cookies.
Netscape simply ported the term over to the world of Webdom in the mid-1990's to designate their variety of persistent identifiers.
As an aside, David has written what may be the definitive history of cookies, "HTTP Cookies: Standards, Privacy and Politics," in Vol. 1, Number 2 of the ACM Transactions on Internet Technology. The abstract reveals the scope of the article: "How did we get from a world where cookies were something you ate and where "nontechies" were unaware of "Netscape cookies" to a world where cookies are a hot-button privacy issue for many computer users? This article describes how HTTP "cookies" work and how Netscape's original specification evolved into an IETF Proposed Standard. I also offer a personal perspective on how what began as a straightforward technical specification turned into a political flashpoint when it tried to address nontechnical issues such as privacy." This is an excellent article on cookies from all perspectives.